
Desde hace un tiempo, muy a menudo me sorprendo a mí mismo maravillado frente a un texto. Pero no porque la historia que cuenta sea impresionante o me esté dando información súper interesante. A medida que mi lista de lecturas ha ido creciendo, también lo ha hecho mi gozo al encontrar pasajes particularmente bien escritos. Además, durante los últimos años he invertido muchas horas intentando crear textos que sean fáciles de leer (no siempre con éxito). De hecho, escribir se ha convertido en una de las tareas que más disfruto en mi día a día y en una afición que practico siempre que tengo un rato libre. Encontrar la manera más precisa de construir distintas oraciones y de combinarlas en párrafos que se encadenan uno tras otro es una especie de rompecabezas que, si bien resulta tremendamente complejo, también me proporciona una gran satisfacción una vez resuelto. Escribo artículos científicos, notas de laboratorio sobre el trabajo diario y los problemas que van surgiendo, código informático, documentación (sobre todo del código informático, pero también de las dudas que me voy encontrando a medida que investigo), publicaciones en esta web, mensajes a familiares y amigos, un pequeño diario personal, guiones para el podcast… vamos, un sinfín de textos en distintos idiomas y con características diferentes.
Aunque la mayoría de lo que escribo me sirve para comunicarme con los demás, hay una fracción muy importante que simplemente es para mí. Por una parte, las anotaciones, que me sirven como pequeño diario. También la documentación, que además de ser un repositorio de cosas que pueden ser útiles en el futuro me ayuda a fijar conocimientos: no sólo me fuerzo a comprender o resolver algo, sino también a escribirlo (a mano, normalmente). Esto conlleva una tarea adicional de síntesis y redacción, en la cual elijo la manera más lógica de explicar cualquier asunto e identifico posibles lagunas que igual no había comprendido al 100%. Por último, algo similar ocurre al anotar ideas, aunque aquí diría que lo más importante es sintetizar la información crucial para usarla más adelante.
Esta escritura más «personal» complementa a la perfección a una de mis maneras favoritas de aprender algo: la discusión. Mis recuerdos favoritos de mi época de estudiante son en los que trabajaba en algún problema con varias personas, haciendo rebotar infinidad de ideas y dudas entre nosotros hasta que dábamos con una solución o algo que se nos había pasado por alto. El puro hecho de verbalizar mi manera de entender un problema o experimento me hacía comprender mejor la situación. En muchas otras ocasiones me sorprendía a mí mismo encontrando la manera de resolver un problema al contarle a alguien en qué estaba atascado. Si bien esas discusiones siguen siendo posibles en el trabajo, hay muchos otros momentos en los que no tienes acceso a otra persona con la que discutir (ya sea porque estás estudiando algo por tu cuenta, porque no quieres compartirlo con nadie más, o porque simplemente estás formándote una opinión sobre algún tema). Y es en esos momentos en los que el hecho de escribir un texto que agrupe mis ideas se ha convertido en una herramienta muy potente.
Escribir puede ser una forma excepcional de poner en orden mis pensamientos, de estructurarlos lógica y ordenadamente. Cuando se trata de temas complejos o con muchos matices, consolidar mi opinión en forma de ensayo me permite no sólo agrupar toda la información en un mismo lugar, sino también analizar mis planteamientos y encontrar pequeñas fisuras o errores. Un primer borrador no es más que una lista de ideas, que son expandidas en siguientes revisiones. Cuando releo uno de mis textos, siempre voy buscando fallos o afirmaciones sin fundamento. En cierto modo, eso sustituye a una discusión en la que una persona plantea sus argumentos (yo, actuando como escritor) y otra los pone bajo estudio (yo, actuando como lector/crítico/editor). Así, en sucesivas iteraciones, logro llegar a un punto en el que estoy conforme con mis planteamientos y, si tengo alguna laguna, se exactamente cuál es y dónde se encuentra. Este proceso es, por tanto, un primer paso tremendamente útil a la hora de abordar cualquier materia, ya que de ahí puedo saltar rápidamente a buscar información sobre asuntos específicos o consultar con alguien que controle el tema más que yo.
Si bien con este proceso suelo conseguir un texto relativamente sólido desde el punto de vista lógico, también intento mejorar progresivamente su «ritmo» para que un posible lector (mi yo del futuro o cualquier persona interesada en el mismo tema si voy a hacer público el texto) tenga la vida más fácil. Trabajo poco a poco en la gramática, buscando que el texto sea lo más correcto posible. Acorto oraciones para agilizar la lectura si localizo información superflua, o las alargo cuando faltan detalles. Elimino repeticiones innecesarias, separo ideas en distintos párrafos, etc. Una vez termino, suelo dejar la pieza «en barbecho» unos días, tras lo cual vuelvo a dar una lectura completa. En este último paso es cuando los pequeños errores que antes había pasado por alto suelen saltar a la vista. Tras resolverlos, el texto está listo para archivar o publicar y no suelo volver a reescribirlo.
La cuestión del ritmo de un texto es algo que siempre me ha llamado la atención, y es que todos nos hemos encontrado con algún libro que «se lee súper fácil» y otros que «es un tostón, no pude terminarlo». A mí me ha pasado muchas veces, y normalmente nunca se exactamente qué es lo que hace que un libro te absorba de esa manera. ¿Es simplemente una cuestión de lo interesante que sea su historia? ¿Tiene que ver con el lenguaje? ¿Los diálogos, quizás? En definitiva, ¿cuál es la clave que otorga a un libro de un ritmo excelente? Es muy probable que alguna vez hayáis leído este fragmento:
Esta oración tiene cinco palabras. Aquí hay cinco palabras más. Las oraciones de cinco palabras están bien. Pero varias juntas se vuelven monótonas. Escuche lo que está sucediendo. La escritura se está volviendo aburrida. Su sonido zumba. Es como un disco atascado. El oído exige algo de variedad. Ahora escucha. Varío la longitud de las oraciones y creo música. Música. La escritura canta. Tiene un ritmo agradable, una cadencia, una armonía. Uso oraciones cortas. Y uso oraciones de longitud media. Y a veces, cuando estoy seguro de que el lector está descansado, lo enfrento con una frase de considerable longitud, una frase que arde con energía y se construye con todo el ímpetu de un crescendo, el redoble de los tamboras, el estruendo de los címbalos – sonidos que dicen escucha esto, es importante.
Gary Provost – 100 maneras de mejorar su escritura
Así que escribe con una combinación de oraciones cortas, medianas y largas. Crea un sonido que agrade el oído del lector. No escribas solo palabras. Escribe música.
En general suelo guiarme más por el sentido común y por cómo siento el texto al leerlo (nunca me he obsesionado contando palabras), pero es cierto que la monotonía suele generar pérdida de interés en el lector (igual que las parrafadas interminables o las repeticiones constantes) y que esta va totalmente en contra de esa inmersión total en la lectura. Dándole vueltas al tema, y por simple curiosidad, hace poco me construí un simple macro en Word que me permite, de una manera muy visual, comprobar si las oraciones de un texto miden siempre lo mismo o van cambiando:
Sub PhraseLenghts()
'
' Checks all phrases in the manuscript, highlights them as a function of their length
'
For Each sntc In ActiveDocument.Sentences
With sntc
If .Words.Count <= 6 Then
.HighlightColorIndex = wdBrightGreen
ElseIf (.Words.Count > 6 And .Words.Count <= 12) Then
.HighlightColorIndex = wdYellow
ElseIf (.Words.Count > 12 And .Words.Count <= 18) Then
.HighlightColorIndex = wdPink
Else
.HighlightColorIndex = wdTeal
End If
End With
Next
End Sub
Este trocito de código en VisualBasic simplemente recorre todas las oraciones (ActiveDocument.Sentences) de un texto en Word (con el bucle for), calcula el número de palabras de cada oración (utilizando la función Words.Count) y resalta la oración con un color en función de dicha longitud (utilizando unos cuantos if y la función HighlightColorIndex). Por ejemplo, este es el resultado cuando lo utilizo con el extracto anterior de Provost:

En verde se resaltan las frases cortas (de seis palabras o menos), en amarillo si tienen entre seis y doce palabras, en rosa si tienen entre doce y dieciocho palabras, y en verde azulado si tienen más de dieciocho palabras. Obviamente estos números son totalmente arbitrarios, y podrían cambiarse o añadirse más categorías en función del número de palabras en cada oración (de hecho, para mí una frase de diecinueve palabras no es muy larga). Cuando dudo sobre el ritmo de alguno de mis textos, puedo simplemente darle a un botón y analizar de un vistazo si hay bloques demasiado extensos del mismo color. Word también proporciona un par de herramientas estadísticas sobre la complejidad (que no el ritmo) de un texto, y ambas se basan en el tamaño medio de las oraciones y el número medio de sílabas de las palabras del texto. La idea aquí es que un texto con frases y palabras cortas resulta fácil de comprender, mientras que otro con frases interminables llenas de palabras largas requiere más atención por parte del lector.
Ahora bien, ¿qué pasa con los grandes autores? ¿Suelen tener en cuenta esa variación de longitudes en sus oraciones? La forma más rápida de comprobarlo es ver un ejemplo. Debajo de estas líneas he subido sesenta y cuatro páginas de uno de mis libros favoritos: Flores para Alguernón (Daniel Keyes, 1959):


Es muy fácil ver que, aunque hay un cierto predominio de las oraciones largas (de nuevo, largas según los números anteriores), no hay ninguna página de un solo color, y lo normal es encontrar pequeñas islas de distintos colores dentro de la mayoría formada por las frases de mayor longitud. También es posible ver fragmentos predominantemente amarillos, que suelen corresponder a los diálogos entre personajes. Si hacemos el mismo análisis en un libro con menos diálogos, lo normal sería ver una tendencia hacia las frases más extensas.
Todo esto está muy bien, pero no deja de ser una manera bastante cualitativa de analizar el tamaño de las frases. Hace unos días estuve pensando en si habría una manera más cuantitativa de comprobar la distribución de longitudes en un texto largo. A priori, no me pareció un análisis muy complejo: sólo hay que recorrer un texto, separar todas sus frases y contar las palabras. Sin embargo, en Word ni existe una función nativa que realice ese proceso ni puede llevarse a cabo de manera sencilla con un macro (al menos que yo sepa).
En ese momento dije: «por suerte, sabes programar, así que ponte manos a la obra que vas a aprender algo nuevo». La tarea no parecía muy difícil, y de hecho se puede resumir en cuatro puntos bastante simples:
1 – Abrir un fichero que contenga el libro en cuestión y almacenarlo en una cadena de texto.
2 – Segmentar la cadena de texto que contiene el libro en pequeñas subcadenas de texto, cada una con una frase.
3 – Contar el número de palabras en cada una de las frases.
4 – Visualizar la distribución del número de palabras (generando un histograma, por ejemplo).
Como suele ocurrir en estos casos, siempre hay algún punto que acaba siendo más puñetero de lo esperado. Si bien los pasos 1, 3 y 4 son triviales (básicamente una línea de código cada uno), segmentar un texto en distintas oraciones presenta algunas sutilezas. Lo primero que se me ocurrió fue buscar cada ocurrencia del símbolo «.» en el documento y utilizarlo para separar las oraciones. Ahora bien, en un libro existen otras maneras de separar frases (los signos de interrogación y exclamación, o los guiones cuando se escriben diálogos), y el punto también aparece dentro de otros signos ortográficos (los puntos suspensivos). Por ejemplo, ¿cómo separaría mi algoritmo la siguiente frase?
El caso es que si lloviese… Mejor no pensar en esa posibilidad.
Si simplemente separo el texto en función de los puntos, la frase se dividiría en cuatro cadenas de texto:
1 – El caso es que si lloviese.
2 – .
3 – .
4 – Mejor no pensar en esa posibilidad.
Cosa que es totalmente incorrecta, y falsearía mi análisis. Del mismo modo, es muy común separar diálogos con rayas o guiones largos, cosa que una simple búsqueda de puntos pasaría por alto. Al comprender que no había tenido en cuenta estos detalles, mi primer instinto fue crear una lista de todos los casos posibles y construir un pequeño algoritmo que los tuviera en cuenta. Sin embargo, rápidamente pensé: «Seguro que no eres la primera persona que ha tenido este problema, busca un poco a ver…». Y efectivamente, procesar textos es un tema en el que la gente lleva décadas pegándose cabezazos contra la pared. En seguida encontré una librería en Python (Natural Language Processing Toolkit, NLTK) con decenas de algoritmos desarrollados especialmente para el procesado de textos teniendo en cuenta todas estas sutilezas. Así, con una simple llamada a la función sent_tokenize es posible dividir una cadena de texto en todas sus frases. Una vez hecho esto, la función nativa split de Python puede trocear cada oración en palabras, y una simple llamada a la función len me dice el número total de palabras. El código entero, junto con una pequeña función para representar el histograma de longitudes, no llega a las cincuenta líneas de texto:
# -*- coding: utf-8 -*-
"""
breaks text into sentences
@author: fer
"""
#%% Import tools
from nltk.tokenize import sent_tokenize
import numpy as np
import matplotlib.pyplot as plt
import h5py
#%% Load data
book_title = 'flores' #pick book title
#'cp1252' or 'utf-8' as encodings
file = open('./data/' + book_title + '.txt', encoding = 'utf-8') #open file
text = file.read() #extract string with full text
#%% Split into sentences and measure their length (words, characters)
sentences = sent_tokenize(text) #split string into sentences
lengths = [] #initialize sentence length
charlength = [] #initialize character length
for sntc in sentences:
lengths.append(len(sntc.split())) #extract sentence length (in words)
charlength.append(len(sntc)) #extract sentence length (in characters)
lengths = np.array(lengths) #convert to array (eases manipulation)
charlength = np.array(charlength) #convert to array (eases manipulation)
#Show some info
print('median: ' + str(np.median(lengths))) #median length
print('mean: ' + str(np.mean(lengths))) #mean length
print('max: ' + str(np.max(lengths))) #max length
print('# de frases: ' + str(len(sentences))) #number of sentences in the text
#%% plot histogram of sentence lengths
fig, ax = plt.subplots(1,1, figsize = (8,4.5))
ax.hist(lengths, bins = np.arange(0.5, np.max(lengths), 1), rwidth = 0.8)
ax.set_xlabel('Número de palabras')
ax.set_ylabel('Número de frases')
ax.set_title(book_title)
plt.show()
Y para el caso de Flores para Alguernón, este es el resultado final:
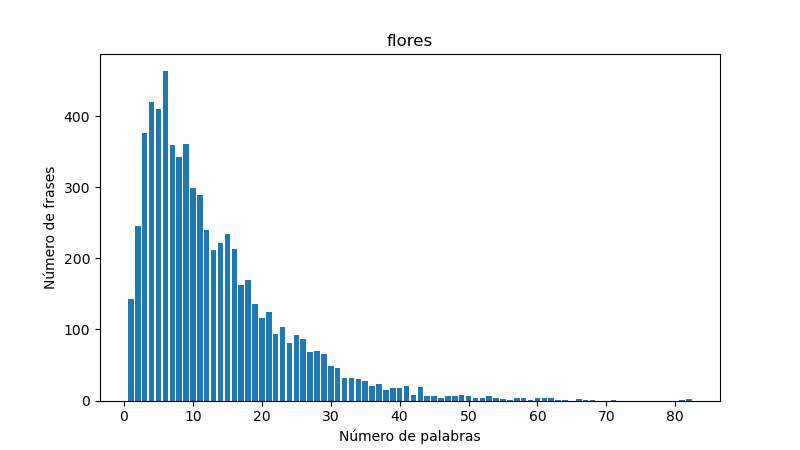
Como puede observarse, la longitud más frecuente para las frases de la novela está por debajo de las diez palabras, y hay una larga cola que llega hasta más de cincuenta palabras.
Aquí, lo que me resulta más interesante no es tanto la distribución de longitudes en sí misma, sino si esta es igual para distintos géneros literarios o autores. ¿Qué pasaría en un texto escrito en inglés? ¿Y en un libro sin diálogos? ¿Son diferentes las novelas de los ensayos? Bueno, afortunadamente esto es muy sencillo de comprobar. Para ello, solo tengo que seleccionar unos cuantos libros de mi biblioteca digital, exportarlos en formato txt utilizando Calibre, y calcular sus histogramas con el código anterior.
Empecemos por la comparativa entre el inglés y el castellano. En este caso he elegido El Señor de los Anillos, dos biografías (una sobre Churchill y otra sobre Napoleón, ambas escritas por Andrew Roberts) y Las Uvas de la Ira, de John Steinbeck:
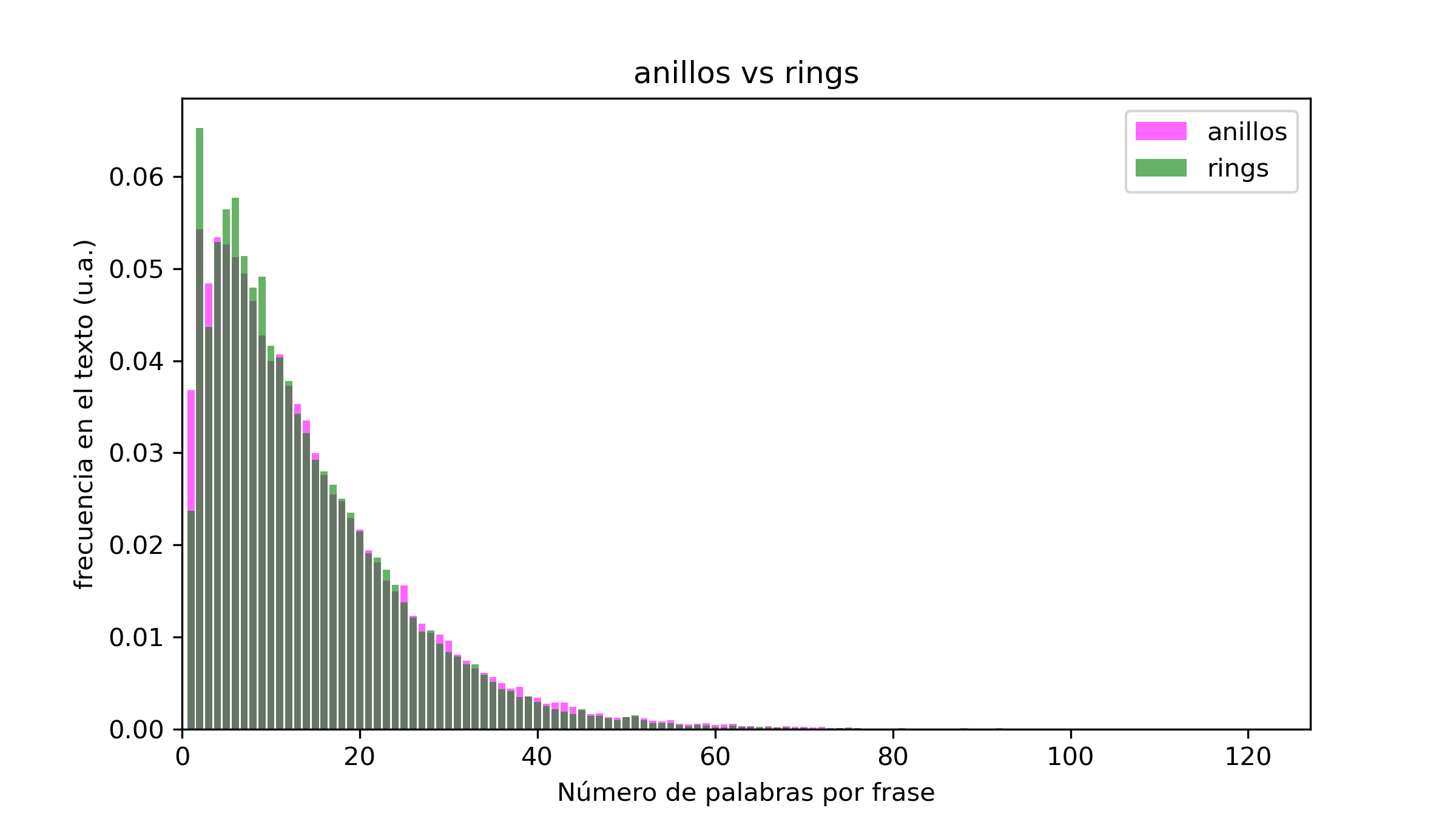
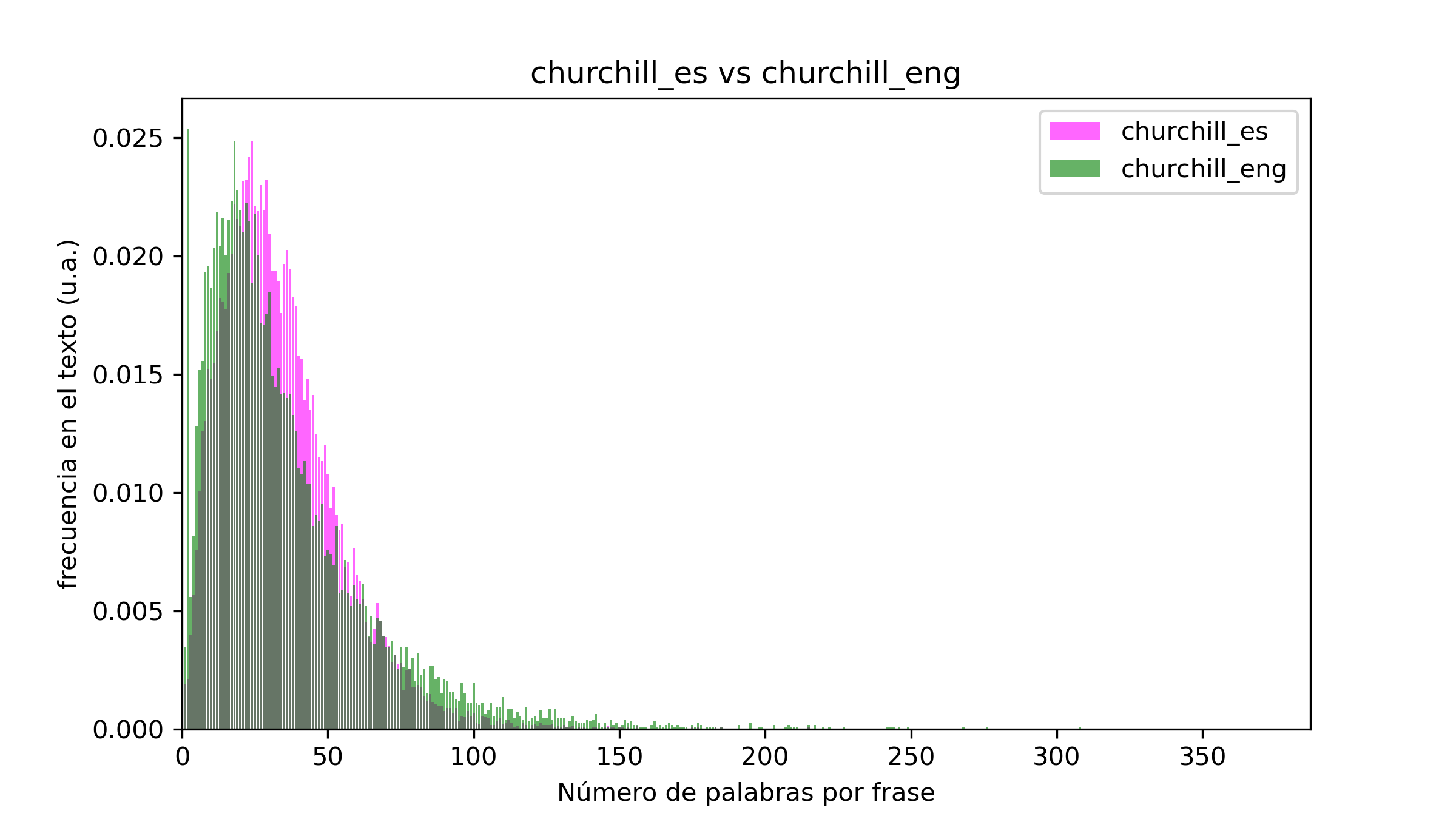
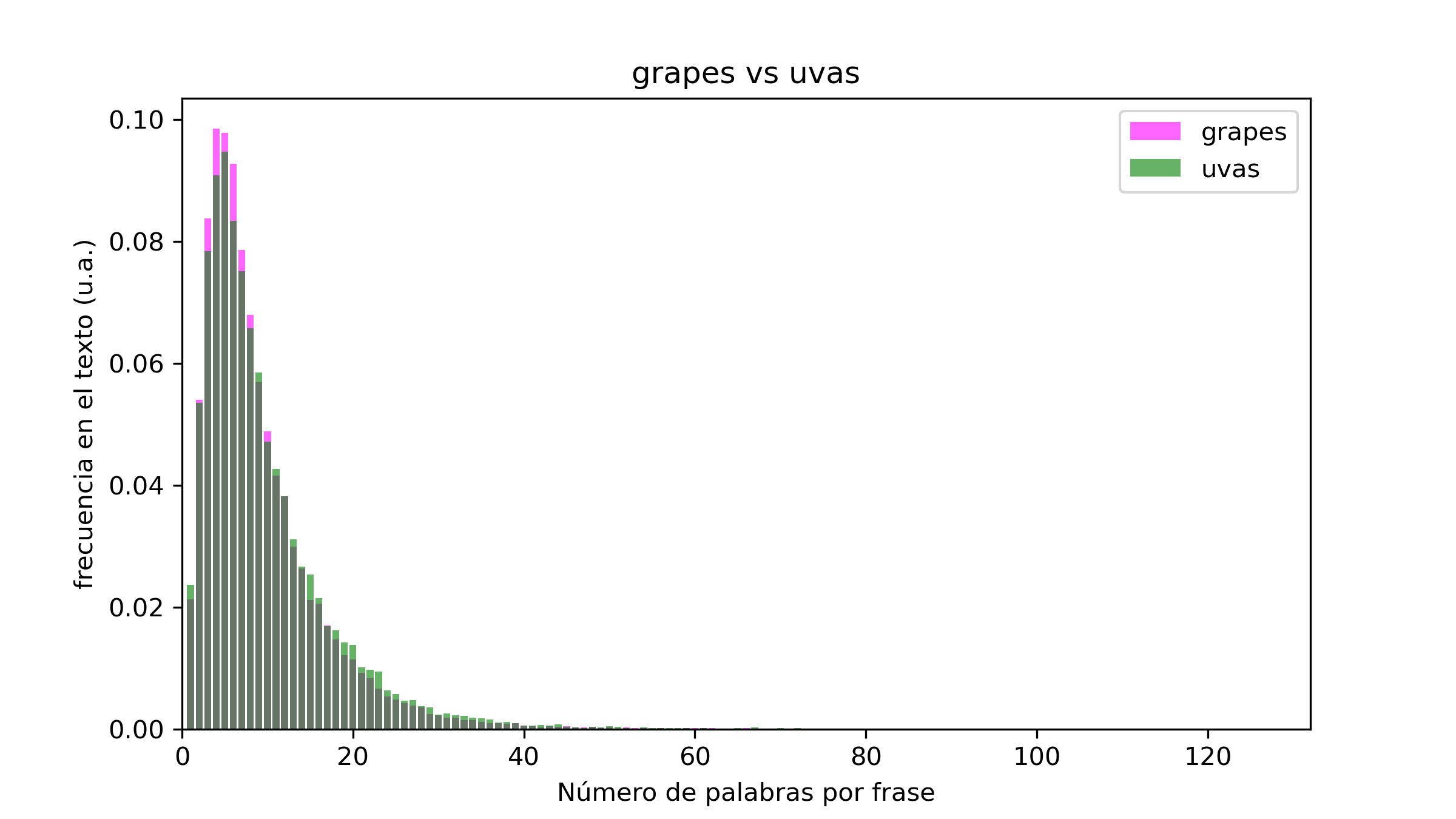
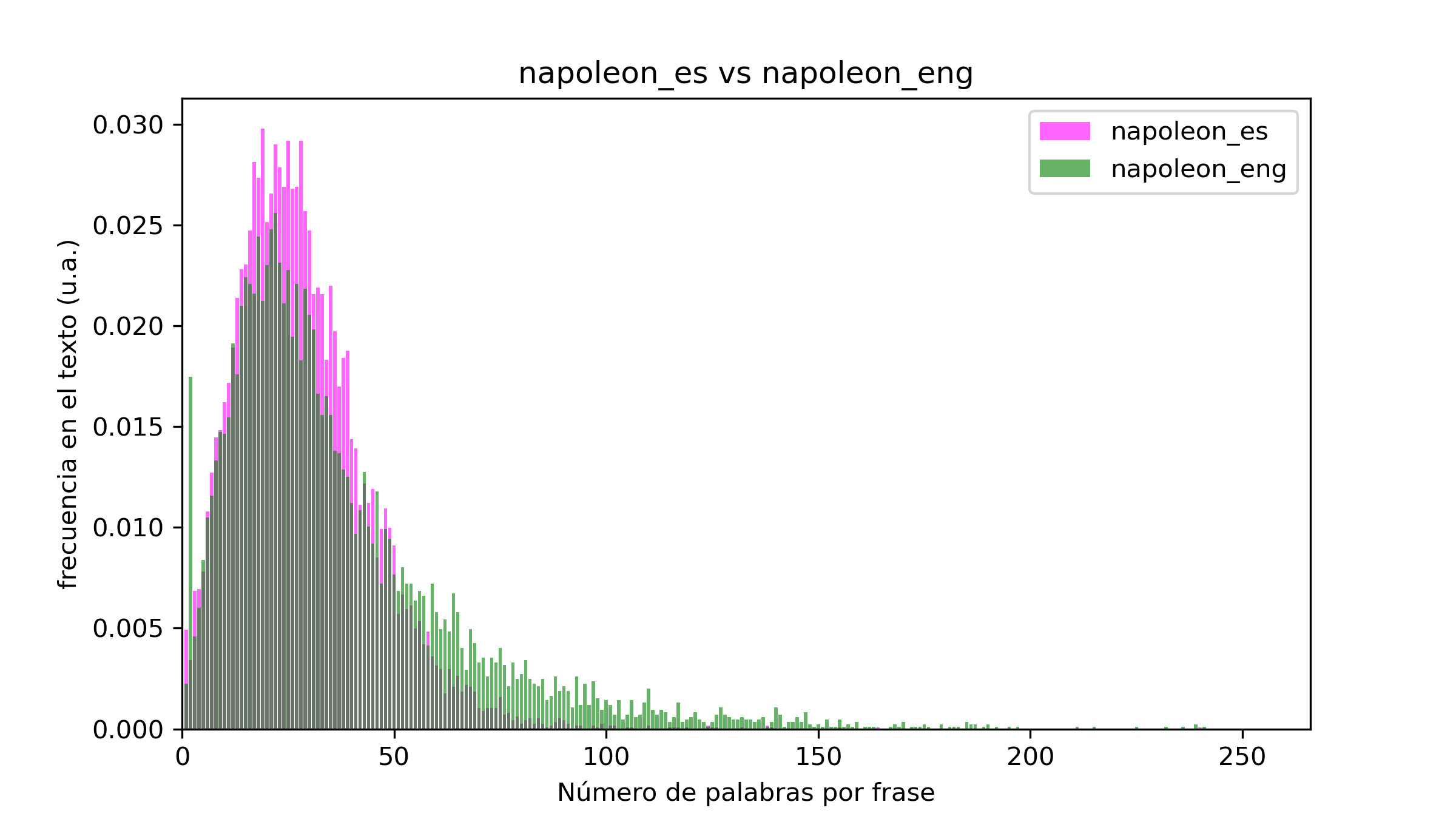
En general, si bien por norma general las oraciones en castellano son más largas que en inglés, los ejemplos no presentan grandes diferencias en ese aspecto. Esto puede deberse a varios motivos. Primero, la muestra es muy pequeña (tan solo cuatro obras). Segundo, el trabajo de traducción realizado puede haber tenido como uno de sus objetivos el mantener la longitud original de las frases (todos los ejemplos son libros originalmente escritos en inglés y traducidos al castellano). Por último, el género del libro puede tener una influencia mucho mayor en la longitud de las frases que la lengua utilizada para escribirlo. Mi teoría es que el primer y último punto son muy relevantes, pero la vida no me da para aumentar la muestra a decenas o cientos de libros. Lo que si resulta fácil y rápido es examinar distintos géneros en el mismo idioma, así que esa es la siguiente comparativa.
Por ejemplo, ¿qué pinta tienen los histogramas de una biografía y una novela? Para ello elegí las biografías de Churchill y Napoleón y las novelas Proyecto Hail Mary (Andy Weir), las Uvas de la Ira y La Única Verdad:

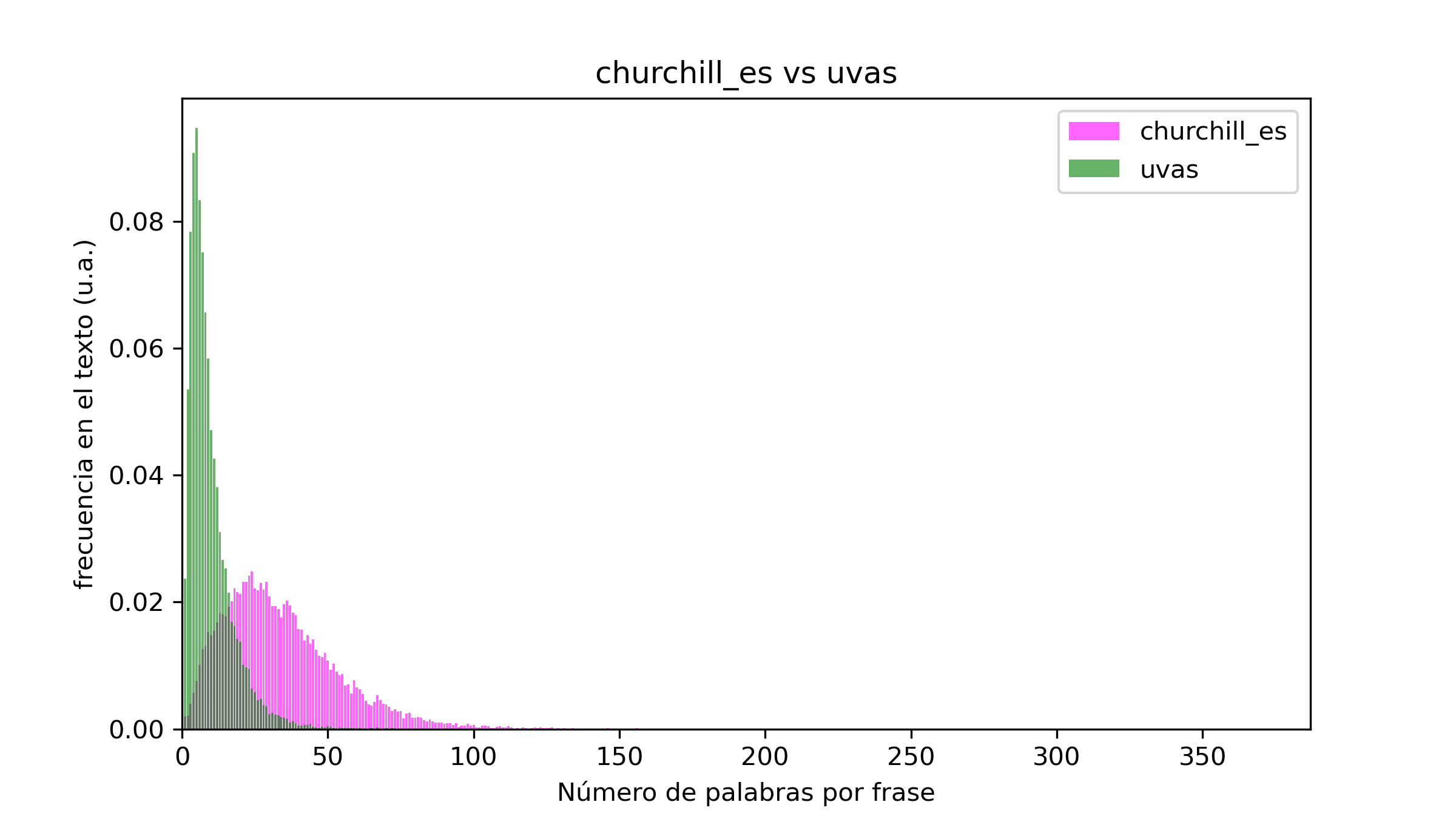
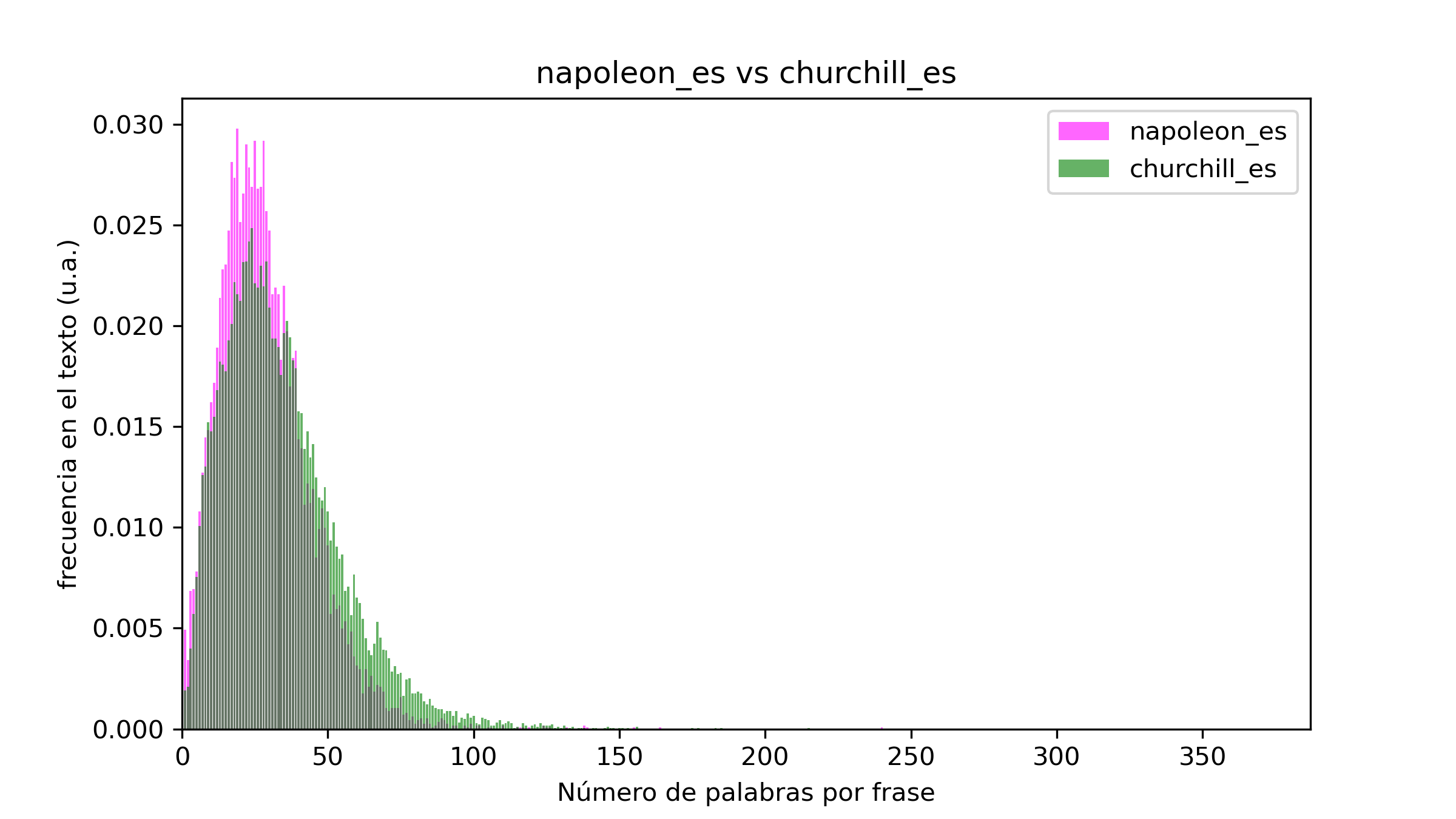

Curiosamente, aquí resulta evidente que las biografías utilizan frases mucho más complejas que las novelas (por muy bien escritas que estas estén). Una parte se debe al hecho de la ausencia de diálogos, pero también a que en muchas ocasiones las biografías introducen largas descripciones muy meticulosas, lo cual ensancha su histograma y lo desplaza hacia promedios mayores de longitud. Esto no ocurre cuando comparamos libros del mismo género, como Proyecto Hail Mary y La Única Verdad, donde los histogramas son prácticamente iguales.
Resumiendo, en función del género, la longitud media de las oraciones cambia bastante (a mayor complejidad existe una tendencia a alargar las frases). Los diálogos suelen estar formados por frases breves, y eso hace que los histogramas de géneros como la novela tengan su pico en las frases más cortas en comparación con otros géneros sin diálogos (igual sería interesante analizar alguna obra de teatro clásico como Macbeth, a ver si ocurre lo mismo). Además, sea cual sea la longitud media de las frases de un texto, los histogramas son anchos, lo cual parece indicar que siempre hay una buena combinación de oraciones largas y cortas. Respecto a los cambios de idioma, parece que las traducciones del inglés al castellano no trastocan mucho la distribución de longitudes de las frases. Por último, aunque asegurarte de que tu texto contiene longitudes de frases variadas puede resultar útil, me inclino a pensar que al final, el género y la temática acaban determinando la longitud media de las oraciones de un escrito. Por mucho que quieras utilizar frases cortas y directas, resulta tremendamente complejo (o incluso imposible) explicar ideas muy elaboradas con frases muy cortas.
Me dejo muchas cosas en el tintero, como por ejemplo ver qué ocurre con la poesía, con las traducciones del castellano al inglés (o a otras lenguas), tener en cuenta el efecto de las comas en el ritmo de lectura, y cientos de ideas que habré pasado por alto. Pero eso lo dejo para otra ocasión. Hasta entonces, creo que la mejor actitud al afrontar la redacción de cualquier texto sigue siendo la de no obsesionarse con este tipo de reglas que, por otra parte, los escritores más famosos del mundo están cansados de pasarse por el forro. En definitiva, escribe sobre algo que te interese y de la forma que te gustaría leerlo.
Deja una respuesta