Mes: noviembre 2017
-

Realization of hybrid compressive imaging strategies
Recently I have been reading a lot about Compressive Sensing strategies. One of the things we always want when we work in a single-pixel architecture is to project the lowest possible number of masks, because the projecting process is the longest in all the acquisition procedure (and it gets longer and longer when you increase…
-
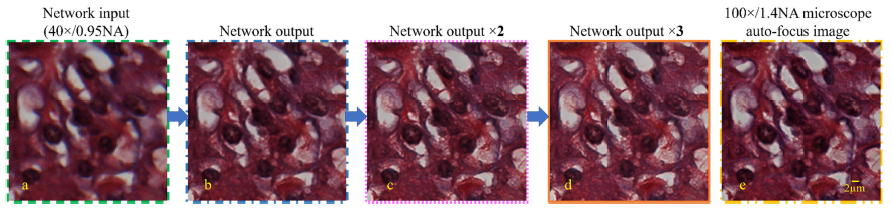
Deep learning microscopy
This week a new paper by the group leaded by A. Ozcan appeared in Optica. Deep learning microscopy, Y. Ribenson et al, at Optica (featured image exctracted from Fig. 6 of the supplement) Abstract, We demonstrate that a deep neural network can significantly improve optical microscopy, enhancing its spatial resolution over a large field of view…
-

Imaging through glass diffusers using densely connected convolutional networks
I just found a new paper by the group of G. Barbastathis at MIT. Imaging through glass diffusers using densely connected convolutional networks, S. Li et al, Submitted on 18 Nov 2017, https://arxiv.org/abs/1711.06810 (featured image from Fig. 3 of the manuscript) Abstract, Computational imaging through scatter generally is accomplished by first characterizing the scattering medium so that…
-
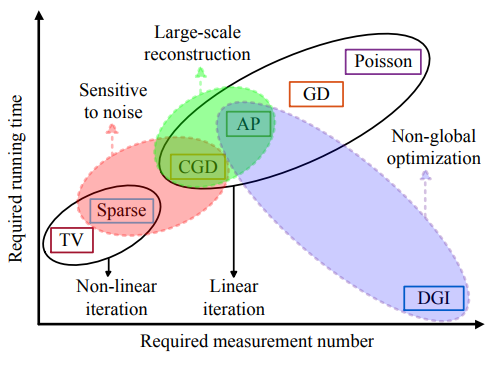
Experimental comparison of single-pixel imaging algorithms
I just read on ArXiv.org that L. Bian and his colleagues made a cool comparison between several ways of performing single-pixel imaging. They have tested the performance on several recovery procedures, some quite familiar but others not so well stablished. I find both Table 1 and Fig. 7 extremely interesting. One sums up really well the…
-
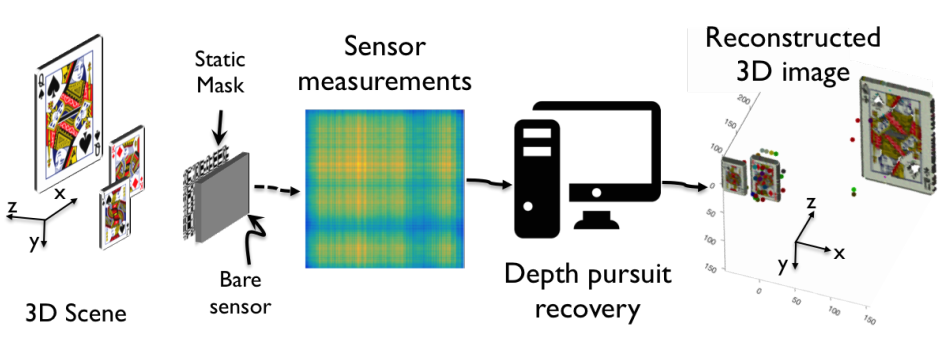
Toward Depth Estimation Using Mask-Based Lensless Cameras
I just discovered on ArXiv.org a new paper by M. Asif, one of the guys behind the FlatCam. Toward Depth Estimation Using Mask-Based Lensless Cameras, M. Asif, submitted November 9th, http://arxiv.org/abs/1711.03527 (featured image extracted from Fig.1 of the manuscript) Abstract: Recently, coded masks have been used to demonstrate a thin form-factor lensless camera, FlatCam, in which a…